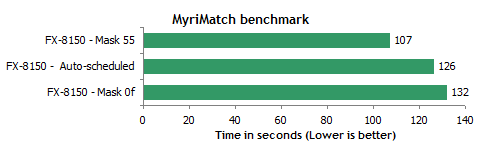
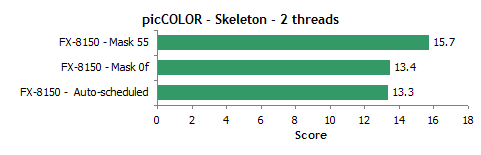fpe wrote:
請問亂序執行都排列出來了,為何又有 A 與 B 依存性的問題???(恕刪)
亂序也可以把 B 丟到 A 前面去啊...
但那只是浪費時間的行為...
不管怎麼排列, 只要 B 一定需要 A 完成的結果
這個依存性就會使兩者的先後次序一定是 A 優先於 B
而不是 A 等於 B , 或 A 排後於 B
如果延伸到後面需要等待的 G
那麼又還是會變成 A 先於 B 先於 G 的問題
亦即不管你要怎麼亂序, 怎麼多核心, 就算一百個核心
也不可能把 A , B , G 分別丟進三個核心內打算只以一個時間單位完成
一定要耗費三個時間單位, 因為 A 必須被完成才能接著做 B , 而 B 被完成後才能接著做 G
所以 G 不可能被排到 B 甚至 A 之前, 這就是定序.
也就是說, 極端平行化的難度最後仍然卡在這個上面.
AMD 的這個設計怎麼看都是要把平行化優化
因此可以合理推測, 若設計得宜
可平行化的日常單純工作, 例如壓縮/ 解壓縮 / 轉檔 ...
這些本身就可以被切成數n個等份同時下去的工作自然是越多核心架構越快處理
然而遇上有先後計算問題的東西, 例如遊戲
仍然會逃不過必要的問題.
(總不會你人才剛從第一關開始, 第五關的某種結局就已經跑出來給你看了, 甚至於你都還不知道過不過得到第三關.)
AMD 的單線程擺明沒優化打算, 先行處理了平行化運算問題
這推土機與其說是想要提升 CPU 核心的效能
不如說是打算避開與 Intel 正面交手比較單線程的效能問題
而改由可多核分工的部份先下手為強.
利用平行化企圖在不同的部份形成互有領先的局勢.
簡單講.
我個人以為, 這不是一個單純家庭或日常用的個人PC要使用的中央處理器設計方向.
而比較像是想做成伺服器, 或工作站, 或特定用途的機器...